
Running ML experiments is mostly waiting. Form a hypothesis, edit code, kick off a training run, check the result, repeat. Andrej Karpathy’s autoresearch hands that loop to an AI agent and lets it run overnight. This guide walks through what it does, why it works, and how to run it yourself.
The repo hit 26,000 GitHub stars in under a week. Shopify’s CEO woke up to a model that outperformed his hand-tuned baseline. Karpathy himself found a bug in his own code that he’d missed for months, caught not by a colleague but by the agent running overnight. These aren’t isolated stories. They’re what happens when you take the most repetitive part of ML research and hand it to something that doesn’t get tired, doesn’t lose focus, and doesn’t get bored after the tenth failed experiment in a row.

The Shift That Makes This More Than a Tool
Most AI tools automate a single task. Autoresearch automates the research loop itself — the cycle where a researcher forms a hypothesis, edits code, runs a training session, checks the result, and decides whether to keep the change. That cycle is the actual work of ML research, and it’s almost entirely mechanical once you have a clear objective and a metric to optimize against.
A good researcher might get through 8 to 10 of these cycles in a full working day, with most of that time spent waiting for the GPU rather than thinking. Autoresearch hands the execution to an agent running 5-minute experiments back to back, without interruption.
What Karpathy identified is that the human’s job is shifting from writing training code to writing research directions. In autoresearch, you don’t touch the Python files at all. Instead, you write program.md — a plain English instruction file that tells the agent what to explore and what constraints to respect. The agent handles the rest.
What Actually Happened When People Used Autoresearch
Before getting into the mechanics, it’s worth spending a moment on what autoresearch actually produced in its first real runs — because the results are what make every design choice in the repo feel earned rather than theoretical.
Karpathy’s Own Run
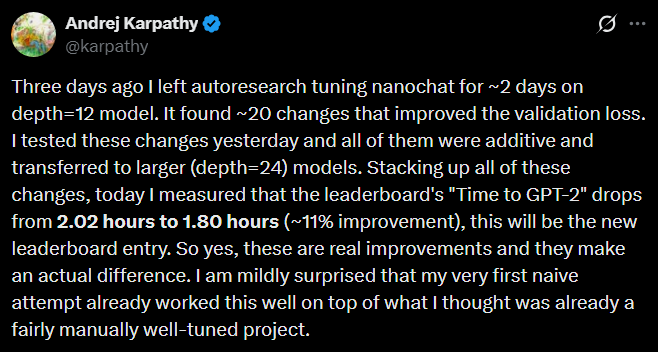
Andrej Karpathy pointed the autoresearch agent at nanochat, his already well-optimized GPT-2 training codebase which he had already spent significant time refining from scratch. Over two days, the agent ran approximately 700 experiments and found around 20 genuine improvements. Stacked together, those improvements cut time-to-GPT-2-quality from 2.02 hours down to 1.80 hours — an 11% speedup on code that one of the best ML researchers in the world had already optimized.
One specific finding that Karpathy himself hadn’t caught before: the agent discovered that the QK-Norm implementation was missing a scalar multiplier, making attention too diffuse across heads. The agent wasn’t doing anything a careful human researcher couldn’t have done. It was just running experiments continuously, without the cognitive fatigue or context-switching that pulls a researcher’s attention away from the task.
Tobi Lütke’s Overnight Run
Shopify’s CEO took the same pattern and adapted it overnight for an internal query-expansion model. He woke up to a 0.8B parameter model that scored 19% higher than his previous hand-tuned 1.6B baseline, a smaller model outperforming one twice its size, because the agent had optimized the architecture for his specific hardware rather than defaulting to “bigger is better.” He then pointed the same loop at a reranker model and beat that baseline too.
Who Autoresearch Is Actually For
The reason autoresearch matters beyond specialist ML researchers is that it changes the economics of ML experimentation for anyone who doesn’t have a large team or a compute cluster.
Small teams at startups don’t have the headcount to run 100 experiments manually. A single researcher might manage 10 in a day, on a good day, when nothing else is breaking. Overnight GPU time becomes an equalizer: the agent runs while the team sleeps, and the morning review is where human judgment goes, not the execution.
Founders building domain-specific models typically start by copying hyperparameters from someone else’s public repo and hoping they transfer to different data and hardware, which they often don’t. Autoresearch gives you a systematic way to find what actually works for your specific setup. The agent doesn’t know or care what the “standard” configuration is; it finds what performs best in your 5-minute window on your GPU, which is the answer that actually matters for your product.
Researchers with more hypotheses than time, which is most researchers, benefit differently. The constraint isn’t usually ideas; it’s the time it takes to test them. Autoresearch removes the execution bottleneck for experiments that fit in a short training run, which means more hypotheses get tested, more dead ends get eliminated quickly, and more time goes toward the work that genuinely requires deep thought. The shift from LLMs to SLMs happening across the industry makes this increasingly relevant — smaller, efficient models optimized for specific tasks are exactly the kind of target this loop is built to find.
[INFOGRAPHIC IDEA: Two-panel diagram — left: “Before autoresearch” showing human cycling through code → train → wait → evaluate with clock showing hours; right: “With autoresearch” showing human writes program.md once, agent handles the loop, human reviews results in morning]
How Autoresearch Works
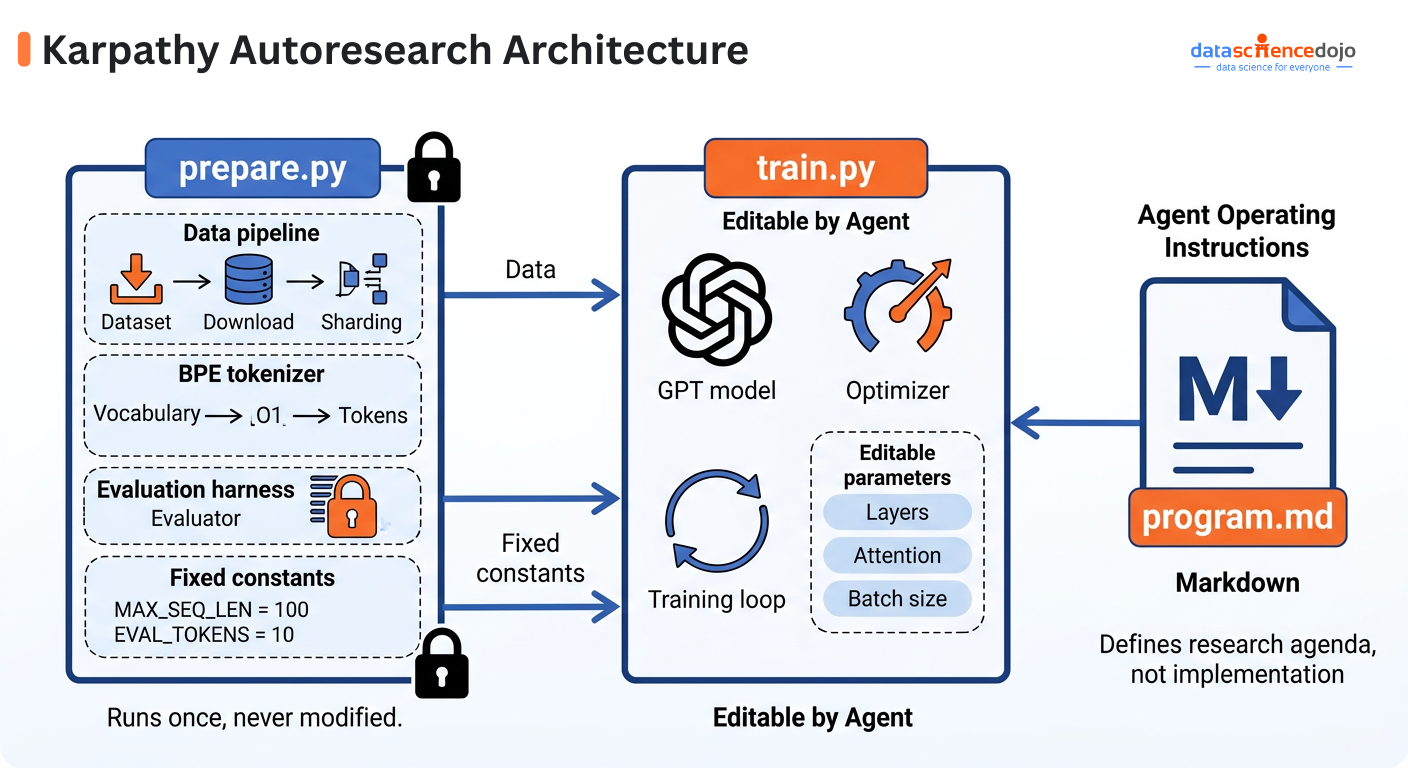
The repo has exactly three files that matter, each with a distinct role:
- prepare.py: Locked after the first run. Handles data download, tokenizer training, and the evaluation function. The agent can never touch this, which is what keeps the scoring honest.
- train.py: The only file the agent edits. Contains the full model architecture, optimizer, and training loop. Everything inside is fair game: layers, attention patterns, batch size, learning rate schedule.
- program.md: The human’s file. Plain English instructions that tell the agent what to explore, what constraints to respect, and how to handle edge cases. This is the research agenda.
The Experiment Loop
Once you’ve handed the autoresearch repo to a coding agent like Claude or Codex, the loop runs like this:
- Read context: The agent reads program.md and the full train.py before touching anything. At 630 lines, the whole codebase fits in context at once.
- Form a hypothesis: The agent decides what to change and edits train.py directly.
- Run the experiment: A 5-minute training session kicks off, with all output redirected to a log file.
- Read the result: The agent extracts two numbers: the validation score (val_bpb) and peak memory usage.
- Keep or revert: If the score improved, the change gets committed to git and becomes the new baseline. If not, git reset snaps the file back to where it was.
- Handle crashes: If a run produces no output at all, the agent reads the last 50 lines of the error log, attempts a fix, and re-runs. After a couple of failed attempts it abandons the experiment and moves on.
- Repeat: The branch only ever advances on genuine improvements. By morning it’s a clean record of every change that actually worked, and a separate untracked results file has the full history including failures.
The Instruction File
The most interesting part of the system isn’t the training code, it’s progam.md. It’s a plain Markdown document, not code, that contains the agent’s complete operating instructions: what the research session is trying to accomplish, what kinds of experiments to run, what the hard limits are, and how to handle edge cases. Understanding what agent skills are helps frame this because that is what program.md basically is. It’s the research agenda written by a human in plain English, and it’s the only thing the human actively maintains across sessions.
Karpathy calls it “programming the research org in Markdown,” which captures something real: the durable artifact from an overnight run isn’t the code changes the agent made, it’s the instruction file that produced them. The default in the repo is deliberately bare-bones, a starting point, not the finished thing, and refining it is where a researcher’s judgment actually compounds over time.
The Scoring Metric
Every experiment is scored on a single number called validation bits per byte, or val_bpb. Lower is better, and it measures how efficiently the model encodes text. The key property is that it doesn’t depend on vocabulary size, which means the agent can try completely different architectures — changing the tokenizer, the number of layers, the attention mechanism — and every result stays directly comparable. A metric tied to vocabulary size would let an agent game the evaluation just by adjusting vocab size; val_bpb closes that loophole and keeps every result honest across the full range of changes the agent might make.
Why the Constraints Are the Point
The reason agentic AI systems so often fail in practice is that they operate in environments too large and ambiguous to navigate reliably. Autoresearch solves this not by building a more capable agent, but by shrinking the environment until a capable agent can operate inside it dependably.
The 630-Line Limit
The entire training codebase is kept to 630 lines intentionally, small enough that the agent can read every line before touching anything. This is how context window memory in agentic systems works most effectively: an agent that has read the full training file understands how every part connects — how batch size interacts with gradient accumulation, how the attention pattern affects memory usage, how changing the optimizer requires updating the learning rate schedule — and makes changes that are coherent rather than isolated patches. As the codebase grows more complex across sessions, that coherence starts to break down. Keeping it small is what keeps the agent effective.
Hard Constraints That Close Failure Modes
Beyond the size limit, the agent cannot modify the data pipeline or the evaluation function, cannot install new packages beyond what’s already declared in the project file, and is told to apply a simplicity criterion: a tiny improvement that adds 50 lines of tangled code isn’t worth keeping. Each constraint closes a specific failure mode. Without the evaluation lock, the agent could rewrite the scoring function to report improvement without actually improving the model. Without the simplicity rule, the codebase grows complex enough that the agent’s coherent understanding of it degrades over successive sessions. These aren’t arbitrary restrictions — they’re what keep the search honest, the results real, and the system useful across hundreds of experiments rather than just the first dozen.
Karpathy’s framing for the whole design is: one GPU, one file, one metric.
What the Agent Is Working With
In autoresearch, the model the agent starts with is a modern GPT-style transformer — the same class of architecture you’d find in production AI systems today. It already incorporates recent research in attention, optimization, and positional encoding, and the agent’s job is to find a better configuration of that starting point for your specific hardware and time budget.
Model size and depth are the most direct levers. Transformer layers stack in sequence, each processing and refining the text representation before passing it on, with an embedding dimension that controls how much information each layer can hold. More layers and wider embeddings produce higher quality, but they’re slower to train and use more memory, within a fixed 5-minute budget, there’s a real tradeoff, and the optimal point depends on your GPU. The agent finds this empirically.
Attention and window patterns determine how the model connects information across a sequence. Full attention across every token is expensive at long sequences, so the architecture uses a mix: most layers apply sliding window attention that only looks at nearby tokens, with periodic global layers that sweep the full sequence. This is controlled by a string like “SSSL”, three local layers for every one global layer, and the agent can experiment with different ratios to find what fits your data and compute budget.
Grouped Query Attention manages memory during inference. When the model processes text, it stores key and value representations for every token it’s seen to avoid redundant computation. By sharing those representations across groups of attention heads, the architecture cuts KV cache memory usage significantly without much effect on quality and the agent can tune how aggressively that sharing happens.
The Optimizer runs two algorithms in parallel. AdamW handles embeddings and normalization layers which is basically a standard across most production LLMs today. Muon handles the core weight matrices by orthogonalizing the gradient before applying it, which finds better solutions faster at this scale than AdamW alone. It’s one of the design choices that reflects genuine recent research rather than just inherited convention, and the shift from LLMs to SLMs makes optimizer efficiency like this increasingly worth understanding.
What the agent cannot change is the dataset, the evaluation function, or the rules of the experiment — those stay locked in prepare.py and constant across every run, which is what makes every experiment’s score directly comparable to every other.
Frequently Asked Questions
What is autoresearch and why did it go viral?
Autoresearch is an open-source framework where an AI agent runs ML experiments overnight — editing training code, scoring results with a single metric, keeping improvements, reverting failures, and looping without human involvement. It went viral because Karpathy shipped real numbers immediately: 700 experiments, 20 genuine improvements, 11% speedup on already-optimized code.
How is this different from AutoML tools like Optuna?
Optuna searches a predefined hyperparameter grid you specify in advance. Autoresearch uses an AI agent that reads and modifies source code directly — so it can rewrite the attention mechanism, change the optimizer, or restructure the training loop, not just tune values in a grid.
Does karpathy’s autoresearch work on GPUs smaller than an H100?
Yes. Community forks for RTX cards (Windows), Apple Silicon (M1–M4), and smaller NVIDIA GPUs are all linked in the GitHub README, along with config guidance for running at smaller scale.
What happens when the agent breaks the training code?
The agent reads the error log, attempts a fix, and re-runs. If it can’t resolve the crash after a few tries, it resets the file via git reset and moves on to the next hypothesis — the overnight run continues regardless.
Are results from one machine comparable to results from another?
No, intentionally. The 5-minute time budget is wall-clock on your hardware, so the optimal config found on an H100 will differ from one found on an RTX 4090. Results are consistent within a single session, which is the comparison that matters.
What should I write in program.md to get better results?
Add specific hypotheses to explore, hard constraints on what’s in or out of scope, and any domain knowledge about your task. The sharper the agenda, the more targeted the agent’s search.
What This Changes About ML Research
The autoresearch repo is packaged as 630 lines of Python under an MIT license, and that packaging matters more than it seems at first. The same autonomous experiment pattern that frontier labs run on compute clusters with teams of engineers is now accessible to any researcher, founder, or small team with a single GPU and an hour of setup. The barrier to systematic, high-throughput ML experimentation has historically been compute cost and engineering overhead — you needed enough GPUs to run experiments in parallel, and enough engineering to build and maintain the infrastructure that orchestrated them. The autoresearch design removes both: the sequential loop on a single GPU is enough to find real improvements overnight, and the infrastructure is already built.
The deeper shift is in what it means to be productive in ML research. The question stops being “how many experiments did you run today?” and starts being “how well did you design the search?” The researcher’s leverage moves to the instruction file, the sharpness of the hypotheses, the quality of the constraints, the domain knowledge encoded in plain English, and everything else becomes execution the agent handles. That’s not a minor workflow change. It’s a reorientation of where human judgment applies in the research process, and autoresearch is the clearest working demonstration of what that looks like at a scale anyone can run. The fact that it fits in a codebase you can read in an afternoon, runs on hardware you already have, and produces real results on the first overnight run is exactly what makes it worth taking seriously now.
Ready to build robust and scalable LLM Applications?
Explore our LLM Bootcamp and Agentic AI Bootcamp for hands-on training in building production-grade retrieval-augmented and agentic AI.