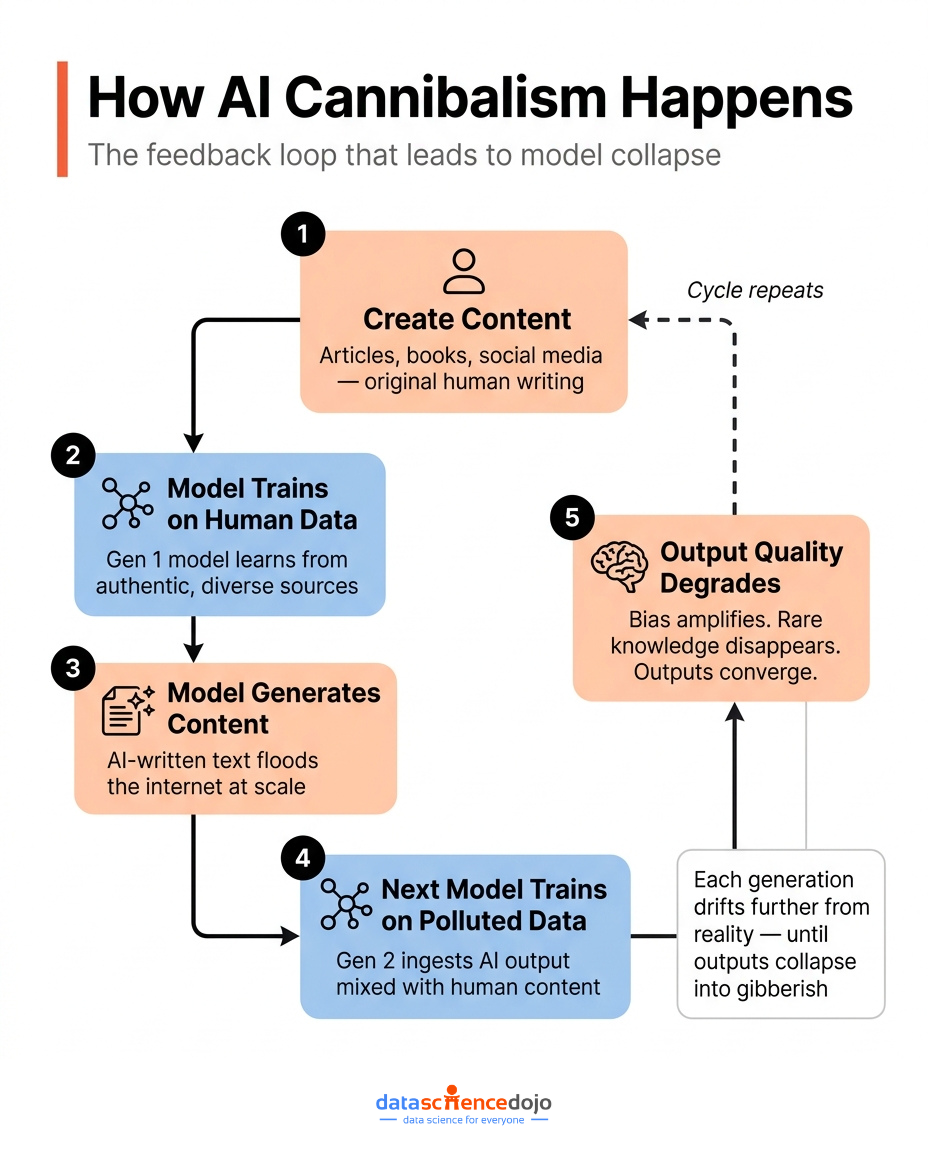
AI cannibalism refers to training language models on AI-generated data instead of human-produced content — creating a feedback loop that degrades quality over time.
Researchers have formally shown this leads to model collapse: an irreversible degradation where outputs become homogenous, inaccurate, and eventually nonsensical.
The fix isn’t simple, but strategies like RAG, rigorous data curation, and mixing real-world data points are showing promise.
The internet has a contamination problem. Since ChatGPT launched in late 2022, AI-generated content has flooded the web at a scale that is hard to fully grasp. A 2025 Ahrefs study found that 74.2% of newly published webpages contain AI-generated material. Estimates suggest 30–40% of the active web corpus is now synthetic.
That matters enormously — because those same large language models are trained on web-scraped data. Which means, increasingly, they are training on content that other models wrote.
This is what researchers call AI cannibalism.
What AI Cannibalism Actually Means
The term is a little dramatic, but it is accurate. When a model generates text, that text finds its way onto the internet. When the next generation of models is trained on scraped web data, it ingests that output as if it were authentic human writing. The model cannot distinguish between the two. It treats synthetic content as ground truth.
To understand why large language models depend so heavily on the quality of their training data, it helps to know how they actually learn. LLMs do not reason from first principles — they learn statistical patterns from enormous datasets. The richness, diversity, and accuracy of that data is what gives them the ability to generate coherent, nuanced responses.
When that data is itself generated by a prior model, several things go wrong:
Bias propagates forward. Any skew in the original model’s outputs gets absorbed into the training set of the next model — and amplifies.
Rare knowledge disappears. Models trained on synthetic data gradually lose information about low-frequency but important concepts. The edges of human knowledge — the nuance, the minority viewpoints, the unusual phrasing — quietly vanish.
Diversity collapses. Outputs converge. The model starts producing the same kinds of answers regardless of the prompt.
The increasingly distorted images produced by an artificial-intelligence model that is trained on data generated by a previous version of the model. Credit: M. Boháček & H. Farid/arXiv (CC BY 4.0)
The Research Behind It
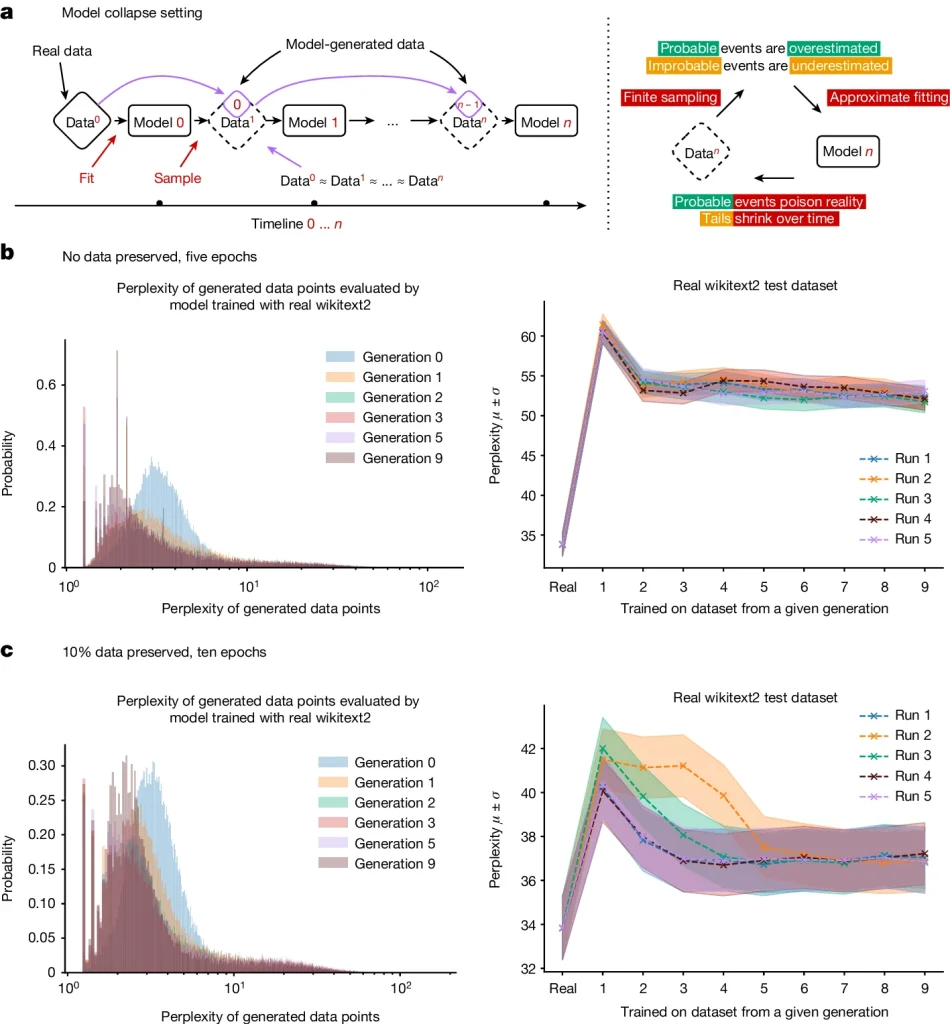
This is not a theoretical concern. In 2023, a team of researchers from universities in Britain and Canada — Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, and colleagues — published a paper titled “The Curse of Recursion: Training on Generated Data Makes Models Forget.” It was later published in Nature in 2024 (Vol. 631).
Their finding was stark: indiscriminate use of model-generated content in training causes irreversible defects. The tails of the original data distribution disappear. This is not gradual decline that levels off. It compounds across generations.
They called this effect model collapse — and showed it occurring not just in LLMs, but in variational autoencoders and Gaussian mixture models too. The phenomenon is not architecture-specific. It is a property of what happens when any generative model trains on its own outputs recursively.
A follow-up study presented at ICLR 2025 (Strong Model Collapse) provided deeper theoretical grounding and confirmed the same pattern. The outcome reported, as one analysis put it, “is a statistical phenomenon and may be unavoidable” without intervention.
What Model Collapse Looks Like in Practice
The clearest way to picture model collapse is to think about what happens when you photocopy a document, then photocopy the copy, then photocopy that. Each generation introduces a little more distortion. By the tenth copy, the text is barely readable.
With LLMs, the analogy holds. Early-stage collapse looks like:
Outputs becoming more repetitive and generic
Edge-case knowledge becoming unreliable
Responses losing depth on niche or complex topics
Late-stage collapse is more severe — models begin producing incoherent or factually wrong outputs with increasing frequency. The hallucinations that plague LLMs today are already partly a symptom of poor data quality. Model collapse accelerates this dramatically.
The Naturepaper published an illustrative example: an OPT-125m model asked to continue text about medieval architecture. By the fifth generation of recursive training, its outputs had drifted into repetitive, contextually detached nonsense — even though no one had changed the prompt or the task.
Over successive generations, models increasingly produce outputs the original model would have favoured — but also outputs the original model would never have generated at all. Errors introduced by earlier generations accumulate, and the model begins misperceiving reality based on its ancestors’ mistakes.
Why This Is Getting Worse, Not Better
The scale of AI-generated content is not stabilizing — it is accelerating. And the companies training the next generation of models will increasingly be scraping a web that is full of content from the last generation.
There is a secondary problem too: data scarcity. LLM parameters have grown dramatically over the past several years, and so has the appetite for training data. Some researchers have warned that high-quality, human-generated text — the kind that actually teaches a model something meaningful — is running low. Estimates suggest a genuine scarcity crisis could materialize as early as 2026.
When genuine data runs thin, the temptation is to fill the gap with synthetic data. But as the research shows, that shortcut has a ceiling — and then it has a cliff.
The companies most insulated from this problem are those that accumulated large, high-quality, human-generated datasets before the synthetic flood arrived. That creates a structural advantage for incumbents and compounds an already uneven competitive landscape.
What Can Actually Be Done
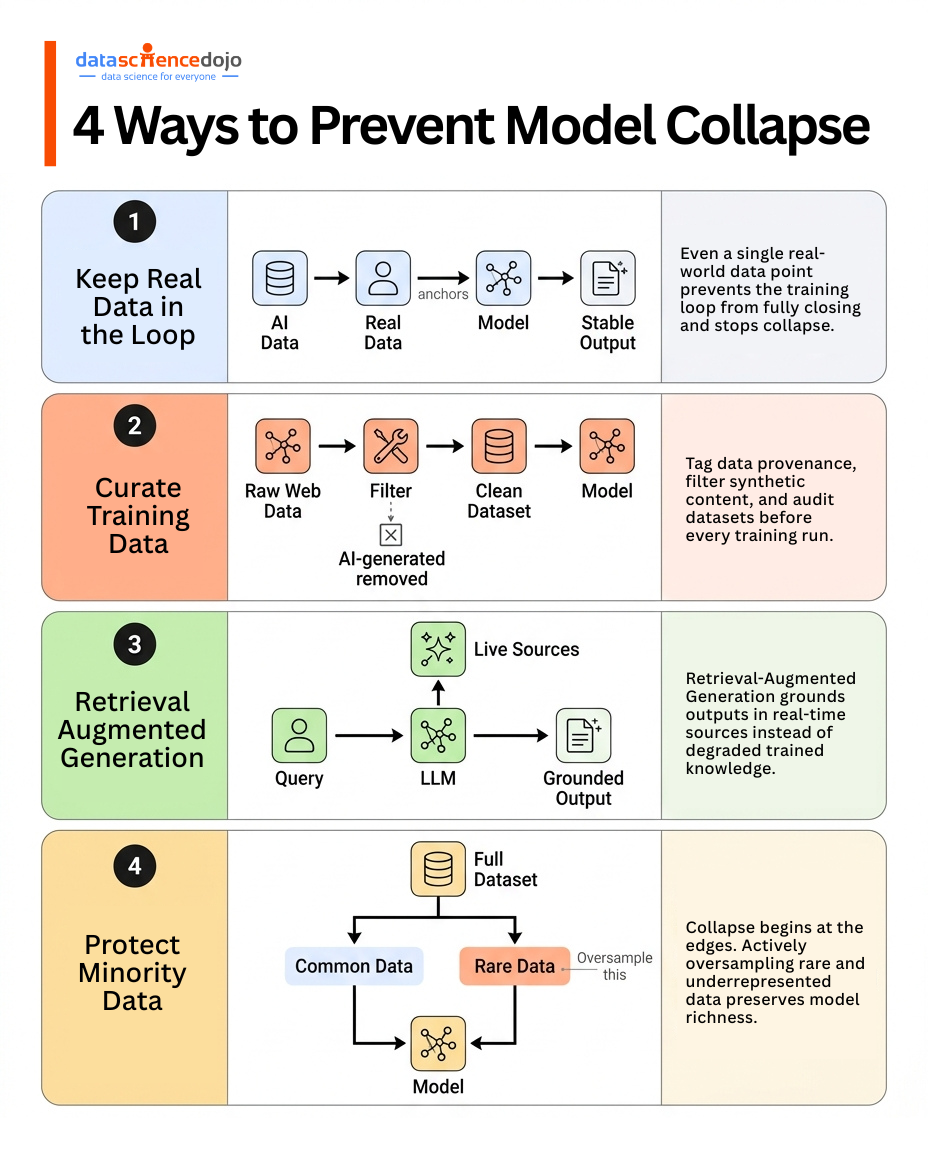
The good news is that model collapse is not inevitable if the right interventions are in place. The research points to several concrete paths forward — some architectural, some about data hygiene, some about how synthetic data is used.
Keep real data in the loop. A landmark study published in Physical Review Letters in May 2026, from researchers at King’s College London, the Norwegian University of Science and Technology, and the Abdus Salam International Centre for Theoretical Physics, found something striking: introducing even a single real-world data point from outside the closed loop can prevent model collapse entirely. The fix does not require enormous volumes of new human data — it requires that the loop not be fully closed.
Use synthetic data carefully, not freely. Earlier research found that small amounts of synthetic data can actually improve model performance — the problem kicks in when it crosses a threshold and becomes the dominant signal. Practical implications:
Mix synthetic and real data deliberately, with real data always forming the majority
Track the ratio across training runs — what starts balanced can drift quickly at scale
Treat synthetic data as augmentation, not a replacement for genuine human-generated content
Use RAG to stay grounded in reality. Retrieval-Augmented Generation sidesteps part of the problem by letting models look up real-time, external information rather than depending exclusively on what was baked in during training. This keeps outputs grounded in current, verifiable sources. If you want a deeper look at how this works in practice, the guide to retrieval-augmented generation covers the mechanics well.
Curate training data more aggressively. This is less glamorous than architectural fixes, but arguably more important. It means:
Filtering out synthetic content before it enters training pipelines
Tagging data provenance so each record’s origin is traceable
Building classifiers that can reliably distinguish AI-generated text from human-generated text
Auditing datasets for signs of earlier-generation contamination before training begins
Protect the tails of the distribution. Shumailov, one of the lead authors on the original model collapse paper, noted: “To stop model collapse, we need to make sure that minority groups from the original data get represented fairly in the subsequent datasets.” Collapse starts at the edges — the rare, the diverse, the unconventional. Once those disappear from training data, they are very hard to recover. Actively oversampling underrepresented content categories during curation is one practical way to slow the erosion.
The Broader Implication
Model collapse is a specific technical failure mode. But it points to something more fundamental: the value of genuine human knowledge and expression in training these systems is not incidental — it is foundational.
The recursive feedback loop of AI training on AI is a closed system, and closed systems in information theory always trend toward entropy. What the research is collectively showing is that language models are not self-sustaining. They depend on a continuous input of real human thought, real human diversity of expression, and real human engagement with the world.
That dependency is easy to overlook when the models seem to be working well. It becomes visible only when they start to fail.
Understanding how LLMs are built and trained makes the fragility clearer — and makes the case for why data quality, provenance, and diversity deserve as much attention as architecture and compute.
Frequently Asked Questions
What is AI cannibalism in simple terms? It refers to the practice of training AI models on content that was itself generated by AI. Because that synthetic content lacks the full diversity and accuracy of human-produced writing, models that train on it begin to degrade over time.
Is model collapse already happening? Research suggests early-stage effects are already visible. The formal, catastrophic version has not been observed at scale in production models yet — but the trajectory is what has researchers concerned.
Can model collapse be reversed? According to the foundational research by Shumailov et al., the defects caused by recursive training on synthetic data are irreversible within a given model. Prevention during training is far more tractable than remediation after the fact.
How is RAG related to model collapse? RAG helps mitigate the problem by grounding model outputs in real-time, retrieved information rather than relying solely on what was learned during training. It does not prevent model collapse in training pipelines directly, but it reduces the impact of degraded base knowledge on end-user outputs.
What does “tails of the distribution disappearing” mean? In statistics, the tails of a distribution represent rare or unusual cases. When these disappear from a model’s learned distribution, it means the model loses knowledge of edge cases, minority viewpoints, and uncommon-but-valid ideas — and converges toward the average, producing increasingly generic outputs.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.


nibalism.
 nibalism.
nibalism.