Gartnerpredicts that by 2028, at least 15% of day-to-day work decisions will be made autonomously through agentic AI. This signals that Agentic AI is rapidly becoming one of the most transformative forces in enterprise technology.
This rise of agentic systems has been significantly driven by Large Language Models (LLMs). Their broad reasoning abilities, flexible problem-solving, and capacity to handle open-ended instructions make them a natural fit for agentic systems. However, as organizations move from experimentation to large-scale deployment, often running several autonomous tasks, the limitations of relying solely on LLMs become visible. LLMs are undeniably powerful, yet also compute-intensive, expensive to scale, and not always the most efficient tool for repetitive, narrow, or predictable workloads that agents frequently execute.
That’s why a major shift is underway. Small Language Models (SLMs) are proving not just viable but often preferable for agentic workloads. Recent NVIDIA’s study underscores this turning point: SLMs are now powerful enough for many agentic tasks, inherently more suitable for specialized operations, and dramatically more economical to run at scale.
In this blog, we’ll dive into why SLMs are rising so quickly, what advantages they unlock for agentic architectures, and how they are reshaping the future of autonomous AI systems.
SLMs are smaller forms of language models that are designed to perform some of the same natural language processing tasks as their larger, better-known large language model (LLM) counterparts, but on a smaller scale.
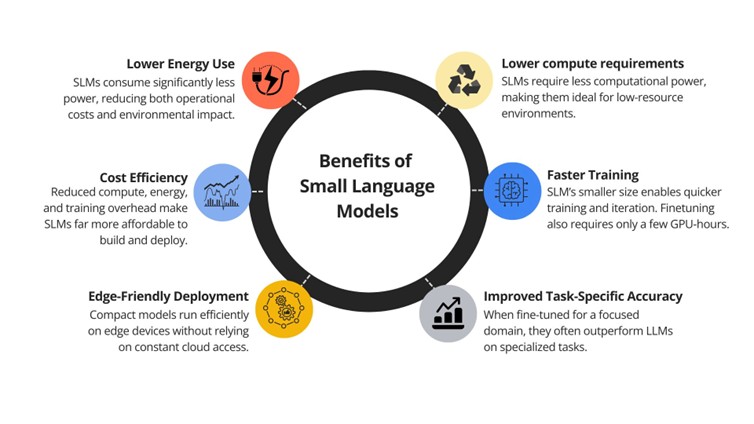
They are trained using fewer parameters, ranging from 2 to 12 billion parameters, and simpler neural architecture. This allows them to operate with less computational power and offer faster inference, which is great for environments where low latency and cost-efficiency are important metrics.
Why SLMs Are Rapidly Becoming the Future of Agentic AI
NVIDIA’s research suggests a major shift in how agentic systems are being built. Instead of relying heavily on LLMs, organizations are moving toward smaller, specialized models that offer speed, efficiency, and better alignment with real-world agent workloads. Here’s why this shift is gaining momentum.
Small Models are Sufficiently Capable
Recent years have shown major advancements in the intelligence of compact models. Tasks that once used enormous language models can now be handled by SLMs effectively. Modern SLMs like Microsoft Phi-3, NVIDIA Nemotron-H, DeepSeek-R1-Distill series, and Hugging Face’s SmolLM2 series are capable of reasoning, coding, and using tools at a level comparable to 30–70B LLMs, yet they produce results faster.
Cost Efficiency that Scales
Because SLMs require far less compute, they instantly reduce the cost of running agentic workloads. This includes inference cost, the cost of fine-tuning, and even the hardware needed to deploy them. A team that previously needed multiple GPUs to run a single large model can often deploy several SLM specialists on a single machine or even on edge devices. For instance, serving a 7bn SLM is 10–30x cheaper (in latency, energy consumption, and FLOPs) than a 70–175bn LLM.
Greater Flexibility in Finetuning
Small Language Models also introduce fine-tuning agility that LLMs simply can’t match. Parameter-efficient to full-parameter finetuning for SLMs require only a few GPU-hours, making it feasible to address evolving user needs, supporting new behaviors, and meeting new output format requirements. Because they’re small, they can be trained, customized, and deployed more affordably without heavy infrastructure.This removes the need for fine-tuning giant models for each small task which can be expensive or expecting the LLM to be a jack-of-all-trade, which can degrade performance for specialized tasks.
Agentic Tasks Favor Smaller Models
Agentic systems naturally break complex tasks into smaller sub-tasks, most of which tend to be repetitive, narrow in scope, and non-conversational. Executing these tasks with a large general-purpose model often requires finetuning, heavy prompt engineering, strict instructions, and careful context management.
With Small Language Models, organizations can deploy a group of specialist SLMs for various agentic routines, one optimized for summarizing documents, another for generating SQL, and another for classification tasks. This frees the system from the overhead of managing long prompts, large context windows, and unnecessary model capabilities.
Adopting SLMs doesn’t mean abandoning LLMs because a Small Language Model can’t handle every task independently. In fact, combining them can be a viable option to improve overall system performance. A large model can act as the “brain” for high-complexity reasoning, while smaller models handle repetitive steps, offering cost-efficiency.
For example, an LLM might plan the steps required to analyze a financial report, then delegate subtasks like extracting figures, classifying expenses, or summarizing sections to Small Language Models fine-tuned specifically for those jobs.
Migration Blueprint: How to Move from LLM to SLM?
Shifting an agentic system from relying on large language models to a more efficient mix of specialized Small Language Models requires careful planning. Below is a simplified, practical migration path:
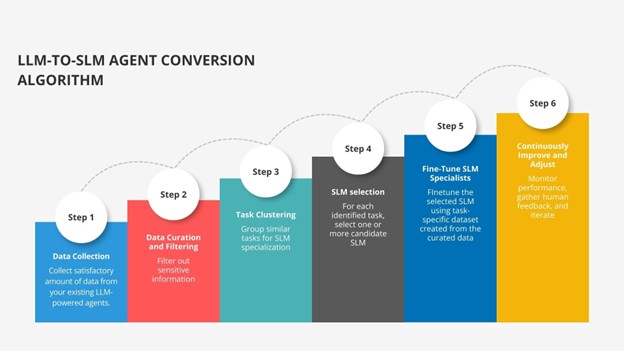
1. Capture Real Agent Usage Pattern
Start by collecting data from your existing LLM-powered agents, including prompts, outputs, tool interactions, and latency. This should be done securely, with proper encryption and access controls. The goal is to understand what your agent does on a day-to-day basis.
2. Clean, Filter, and Anonymize
Once you’ve gathered enough examples, clean the data. Remove sensitive information such as PII or proprietary content. Automated detection tools or paraphrasing can help keep data safe while preserving task structure.
3. Identify Task Patterns
Analyze the collected data to identify recurring patterns of requests or internal agents. You might notice clusters based on identified patterns like document summarization, extraction tasks, recurring code generation patterns, or classification actions. Each cluster represents a potential candidate for Small Language Model specialization.
4. Choose the Right SLM for each Task
For every identified cluster of tasks, select the Small Language Model that is well-suited to the job, considering model size, capabilities, context window, and compute requirements.
5. Fine-Tune SLM Specialists
Create training sets from the curated clusters and fine-tune the chosen Small Language Models to become task experts. Techniques like LoRA or QLoRA make this process economical, while knowledge distillation can be used to transfer useful behavior from the LLM to the smaller model, enabling the SLM to mimic the outputs from the LLM.
6. Continuously Improve and Adjust
Continuously monitor performance, gather human feedback, and refine guardrails. As usage evolves, retrain or update Small Language Models and refine routing rules so that only complex tasks get escalated to a large model. Over time, most of your workload naturally shifts to efficient SLM specialists.
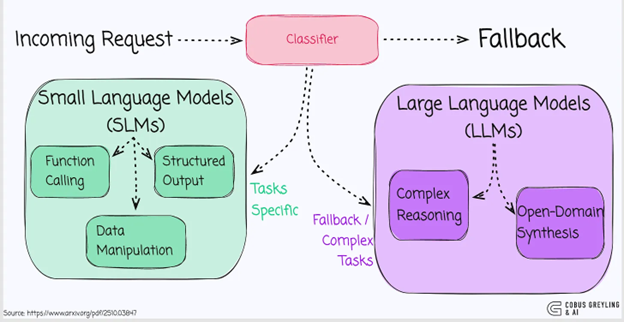
SLM-default architecture provides a practical path for shifting toward smaller models by assigning most agentic tasks to Small Language Models and calling on LLMs only when truly necessary.
source: https://www.arxiv.org/pdf/2510.03847
In this heterogeneous setup:
Every request is routed to SLM first.
The output is validated using confidence scores, task-type rules, or domain-specific metrics.
If the response is acceptable, execution continues.
If not, the task is escalated to an LLM for deeper reasoning or more complex generation.
This design dramatically improves cost efficiency, latency, resource usage, and overall control, while still maintaining performance on tasks that truly require LLM-level intelligence.
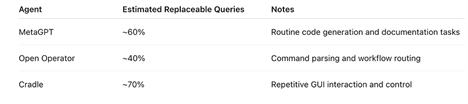
NVIDIA’s research presents practical examples using three widely used open-source agents, MetaGPT, Open Operator, and Cradle, to explain how much of their workload could realistically be handled by SLMs instead of LLMs.
This study shows that many agentic operations, which are narrow, repetitive, and task-specific, don’t require the broad reasoning capabilities of a large model. This makes Small Language Models not only sufficient but often more efficient and better aligned with real agent workloads.
Small Language Models: Agentic AI’s Next Leap
As agentic systems continue to gain momentum, their real-world adoption is revealing both opportunities and constraints. Agentic AI is no longer just a research concept—it is becoming a core part of enterprise automation. Gartner projects that 33% of enterprise software applications will incorporate agentic AI by 2028, signaling rapid mainstream adoption.
On the flipside, Gartner also warns that a portion of these initiatives may be cancelled by 2027, with rising operational costs cited as a major barrier. This makes it clear that the future of agentic AI isn’t about building ever-larger models, but about designing smarter, cost-aware architectures.
By letting SLMs handle the majority of predictable, repetitive tasks and reserving LLMs only for tasks that require broad reasoning or complex tasks, organizations can achieve far better cost-efficiency and control without compromising on performance.This shift toward heterogeneous system promises a more sustainable, scalable, and economically viable future for agentic AI.
Ready to build robust and scalable LLM Applications? Explore Data Science Dojo’s LLM Bootcamp and Agentic AI Bootcamp for hands-on training in building production-grade retrieval-augmented and agentic AI systems.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.