Claude Sonnet 5 is Anthropic’s most capable mid-tier model to date, with substantially stronger performance in reasoning, coding, tool use, and agentic tasks than its predecessor, Sonnet 4.6.
It runs at near-Opus 4.8 performance levels at a significantly lower price, making it Anthropic’s clearest value-for-money option for production AI systems.
Developers can access it now via the Claude API using the model string claude-sonnet-5, with introductory pricing of $2 per million input tokens and $10 per million output tokens through August 31, 2026.
Anthropic released Claude Sonnet 5 on June 30, 2026. It is the most capable version of the Sonnet series to date, and the first Sonnet model to credibly compete with the Opus tier on agentic tasks at a fraction of the cost.
For developers building with Claude, this is a meaningful shift. The previous gap between Sonnet and Opus meant you had to choose between budget and capability for complex multi-step work. Claude Sonnet 5 narrows that gap to the point where many teams won’t need to choose at all.
Here’s what changed, what the benchmarks actually show, and what it means for teams building with LLMs today.
What Claude Sonnet 5 Is Built For
The Sonnet tier was where agentic AI first proved itself. Claude Sonnet 3.5, 3.6, and 3.7 were the models that gave developers real confidence in tool use and coding pipelines. But for a while, the most visible gains in agentic capability moved up to Opus-class models.
Claude Sonnet 5 brings those gains back into the mid-tier. It is built explicitly to plan, use tools like browsers and terminals, and run autonomously at a level that previously required larger and more expensive models. Anthropic describes it as the most agentic Sonnet model yet and the benchmark data supports that claim.
How Claude Sonnet 5 Benchmarks Against Earlier Models
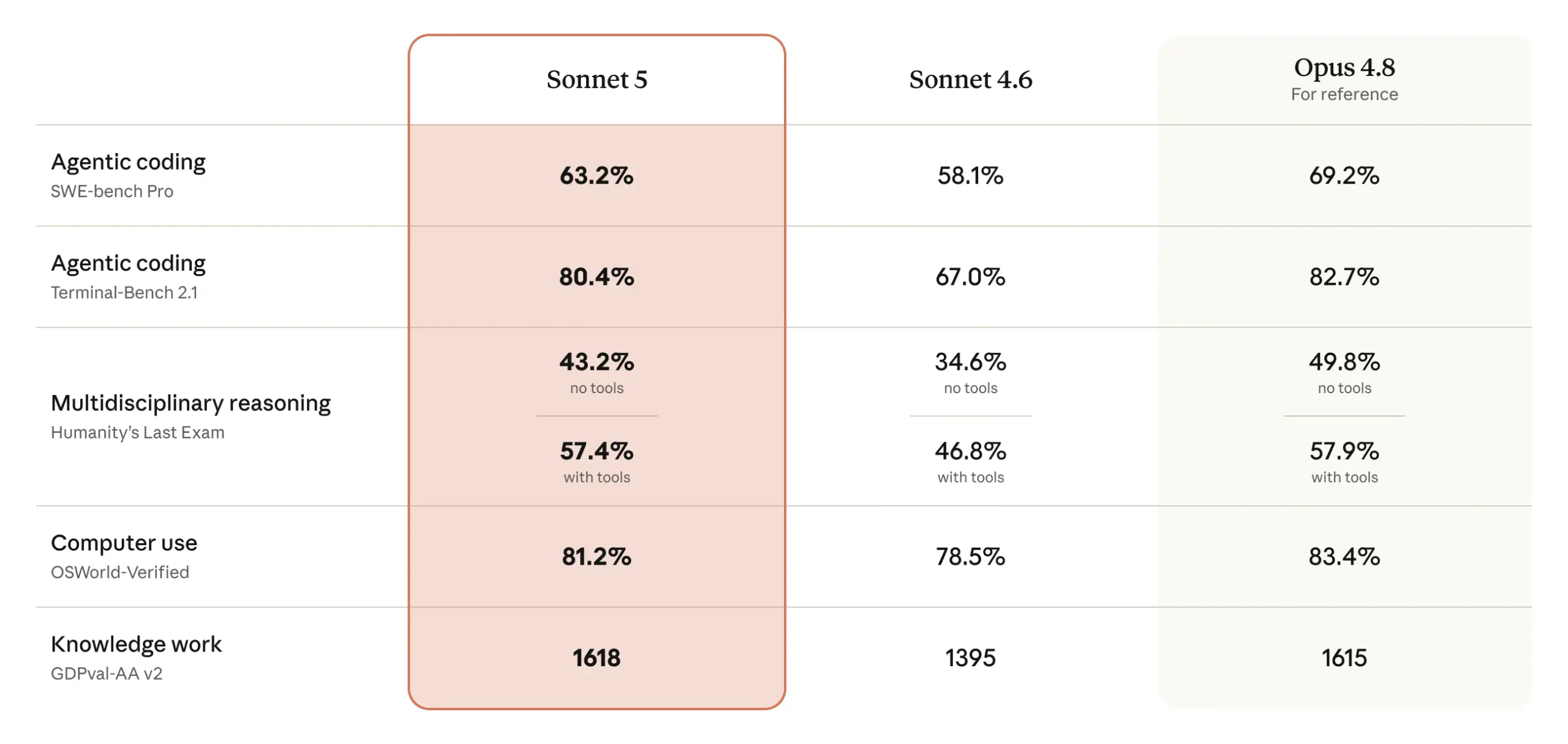
Anthropic evaluated Claude Sonnet 5 across a range of standard benchmarks comparing it to Sonnet 4.6 and Opus 4.8.
Key benchmark improvements over Sonnet 4.6:
SWE-bench Pro (Agentic Coding): Sonnet 5 scores meaningfully higher, reflecting stronger code generation and bug-fixing across real pull requests
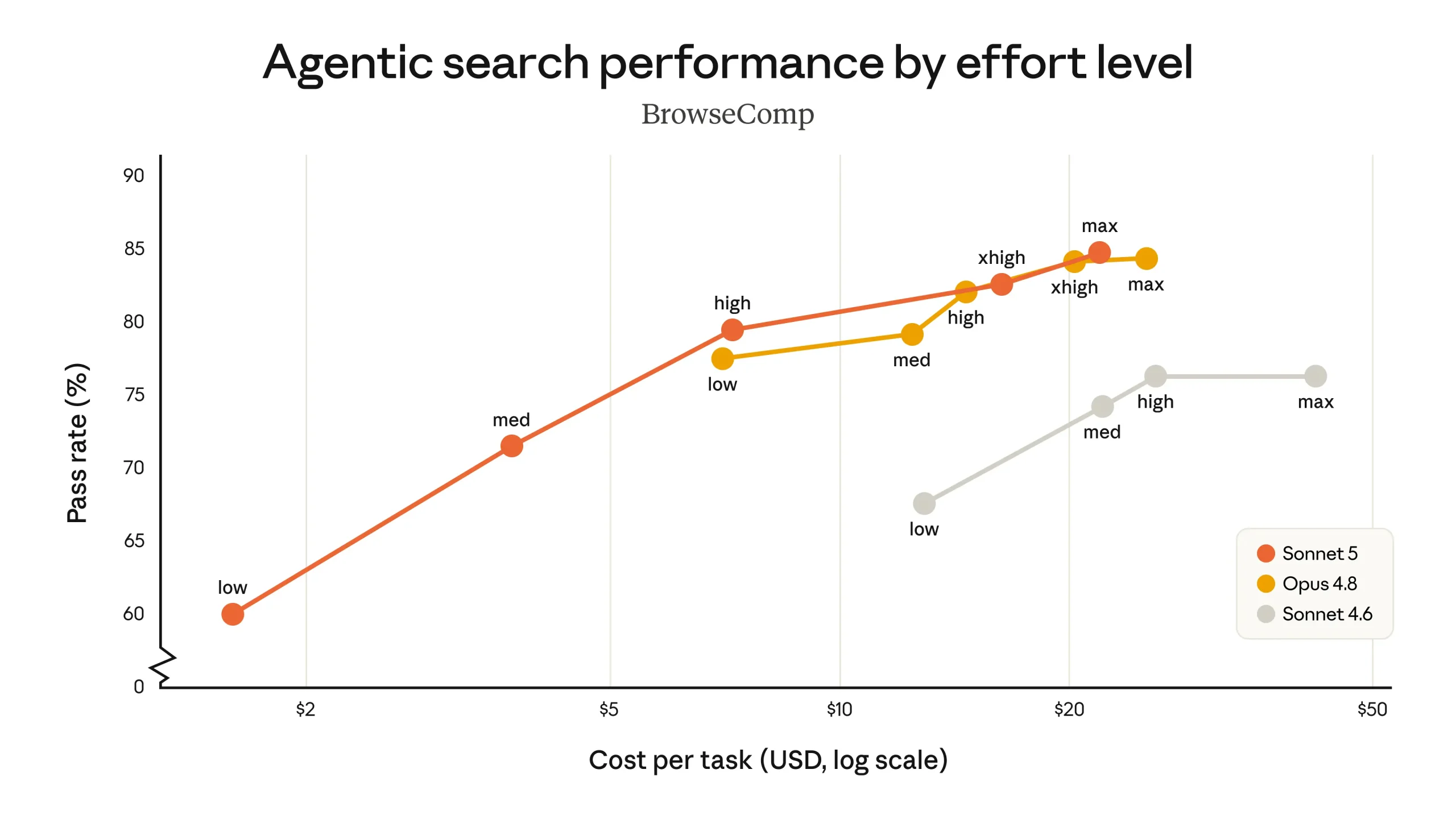
BrowseComp (agentic search): Sonnet 5 outperforms Sonnet 4.6 at every effort level, with higher-effort runs approaching Opus 4.8 performance
OSWorld-Verified (computer use): Strong gains in real-world task completion on desktop environments
Humanity’s Last Exam: Improved performance across domain-specific knowledge in finance, law, medicine, and STEM
The more telling comparison is the cost-performance curve. At standard pricing ($3/MTok input, $15/MTok output after August 31), Claude Sonnet 5 covers a wider range of cost-performance options than Sonnet 4.6, and in several task categories matches what Opus 4.8 achieves at a price that is roughly 40% lower.
During the introductory period through August 31, 2026, that advantage grows further. Introductory pricing at $2/MTok input and $10/MTok output brings the effective cost well below what the standard pricing curve shows.
What Early Access Teams Reported about Claude Sonnet 5
Anthropic shared feedback from teams that tested Claude Sonnet 5 before release. A few observations from engineers across different use cases:
Cursor developers noted that agents “stay on plan, follow conventions, and ship clean multi-step changes, all at an efficient cost”
Engineers testing brownfield code; race conditions, hidden tests, and legacy debt, found that Sonnet 5 traces failures to root causes instead of patching symptoms
Teams running multi-step automation tasks (updating Salesforce, triggering outbound campaigns) reported that Sonnet 5 completed end-to-end jobs that previously stalled halfway
One Rust engineer described Sonnet 5 writing a reproducing test, implementing a fix, and stashing changes to verify the bug reappeared. All in a single pass, without being explicitly asked
The common thread: Sonnet 5 completes tasks where previous Sonnet models would stop short. For agentic workflows, that follow-through is the actual capability that matters most.
What Builders Should Know About Claude Sonnet 5 Pricing and Availability
Claude Sonnet 5 is available today across all Anthropic plans:
Free and Pro plans: Sonnet 5 is now the default model
Max, Team, and Enterprise plans: Available as a selectable model
Claude Code: Available with increased rate limits
Claude API: Accessible via the model string claude-sonnet-5
Pricing breakdown:
Period
Input (per million tokens)
Output (per million tokens)
Introductory (through Aug 31, 2026)
$2
$10
Standard (from Sep 1, 2026)
$3
$15
Opus 4.8 (for reference)
$5
$25
One technical note worth knowing: Claude Sonnet 5 uses an updated tokenizer that processes text differently from Sonnet 4.6. The same input can map to 1.0 to 1.35 times more tokens depending on content type. Anthropic set introductory pricing to make the transition roughly cost-neutral, but enterprise teams should run cost analyses on their specific workloads before assuming headline pricing applies directly to their usage.
Rate limits have also been increased across Chat, Cowork, Claude Code, and the Claude Platform to accommodate the higher token usage that comes with extended effort levels.
The Claude Sonnet 5 Cost Tradeoff You Should Know Before Deploying
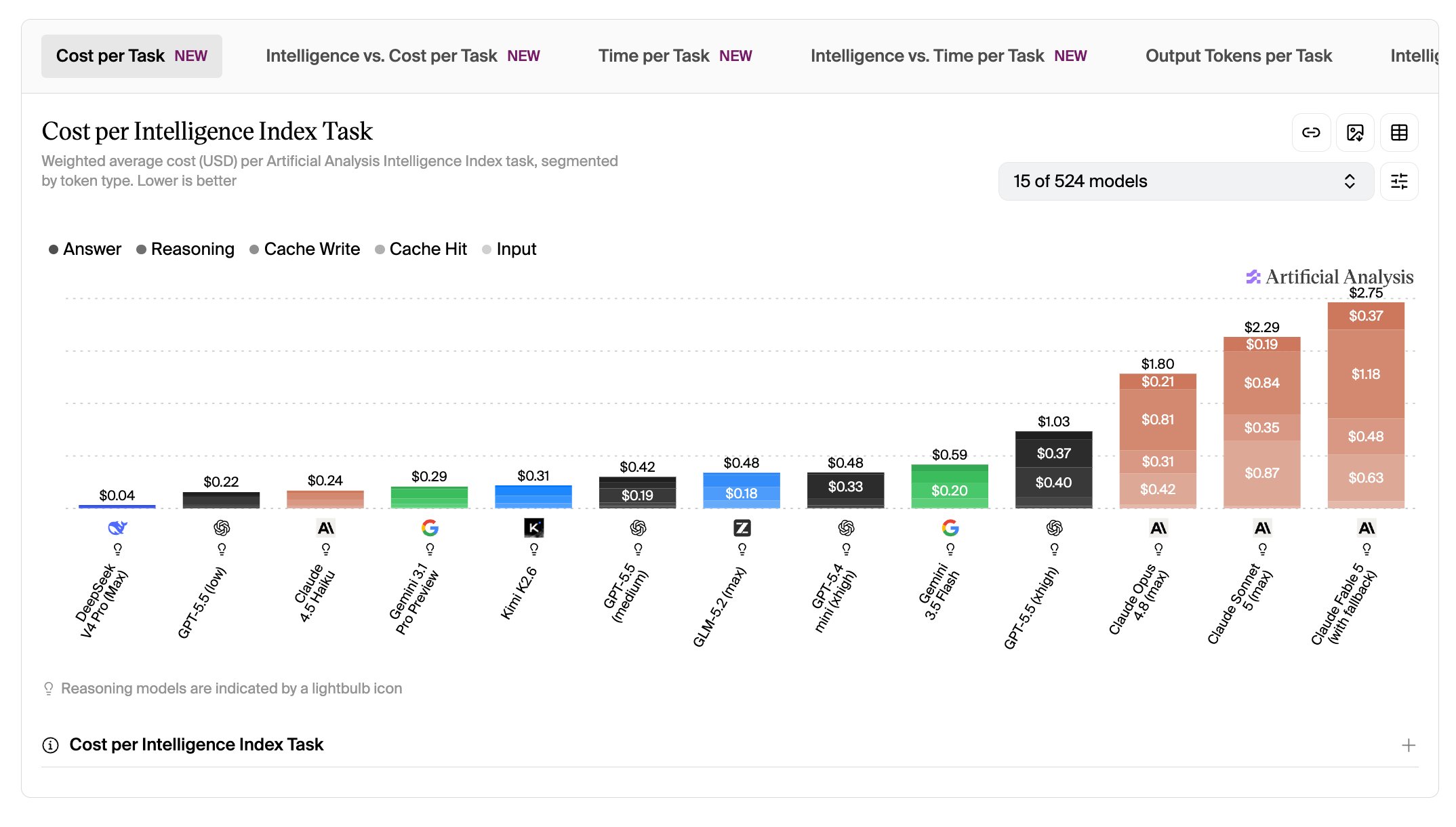
Per-token pricing tells one part of the story. Actual task cost tells another.
Data from Artificial Analysis’s Intelligence Index shows that Claude Sonnet 5 (max) costs more per completed task than Claude Opus 4.8 despite having lower per-token rates. The reason: Sonnet 5 generates nearly 2x as many output tokens per task as Opus 4.8. When a model is more thorough in how it works through a problem, the output volume adds up fast.
This does not mean Claude Sonnet 5 is overpriced. It means the capability gains come with a higher token footprint, and teams optimizing for cost per task rather than cost per token need to account for that difference. If your workload is output-heavy; long code completions, detailed reasoning traces, multi-step agentic outputs, the effective cost of Sonnet 5 at max effort may be higher than the headline rate suggests.
A good way to decide would be to benchmark Claude Sonnet 5 on your actual task distribution before committing. The introductory pricing window through August 31 is a low-risk time to run that comparison against your current setup.
What This Means for Teams Building Agentic Systems
The release of Claude Sonnet 5 is most significant for teams building in the space where agentic LLMs do real work: multi-step pipelines, automated coding workflows, tool-heavy agents, and tasks that require sustained follow-through.
For a long time, building reliable agentic systems with a mid-tier model meant accepting that the agent would often stop short on complex tasks or require more human intervention than expected. The pattern we cover in loop engineering design patterns for AI builders, where reliable iteration depends on the model finishing what it starts, is exactly where Claude Sonnet 5 shows its improvement over Sonnet 4.6.
If your team is running Claude Sonnet 4.6 in production today, the upgrade path is straightforward: swap in claude-sonnet-5 and evaluate on your own task distribution. Given the introductory pricing through August, the timing makes that testing low-risk.
If you’re evaluating models across providers, the comparison now looks different than it did six months ago. When we benchmarked Kimi K2.6 against Claude Sonnet 4.6 earlier this year, the two were competitive across standard coding tasks. With Claude Sonnet 5, Anthropic is raising the baseline that comparisons need to clear.
How Claude Sonnet 5 Fits Into the Broader Claude Model Family
It helps to see where Sonnet 5 sits relative to Anthropic’s full lineup:
Claude Haiku 4.5: Fast, lightweight, lowest cost — best for high-volume, lower-complexity tasks
Claude Sonnet 5: Mid-tier with near-Opus performance for agentic work — the new default for most production use cases
Claude Opus 4.8: Most capable on complex reasoning and cybersecurity-adjacent tasks — still the right choice where safety margins and task difficulty demand it
Claude Fable 5: Anthropic’s strongest publicly available model, returning today after a brief export control suspension
For most developers, Claude Sonnet 5 fills the middle more completely than any previous Sonnet model. It is capable enough that many teams who were paying for Opus will find Sonnet 5 handles their workload at lower cost. And for teams that were running Sonnet 4.6 because they needed efficiency, Claude Sonnet 5 delivers meaningfully better results at comparable pricing.
Practical Guidance: When to Use Claude Sonnet 5
Use Claude Sonnet 5 when:
You’re building multi-step agentic workflows that require planning, tool use, and follow-through
You’re running coding agents that need to debug, test, and iterate rather than just generate
You need Opus-level capability at a lower cost and your task doesn’t require the highest end of cybersecurity or advanced research work
You’re currently running Sonnet 4.6 and want a drop-in improvement without changing infrastructure
Continue using Opus 4.8 when:
Your tasks require the highest available capability and you’re not cost-constrained
You’re working in cybersecurity contexts that need reduced guardrails through the Cyber Verification Program
You’re running tasks where Sonnet 5 at extra-high effort still doesn’t meet the quality bar
For teams working through how to structure agents for complex tasks, deciding when to let agents decide versus enforcing tighter control, our breakdown of open source tools for agentic AI development covers the orchestration layer that sits above model choice.
Understanding what makes an agentic LLM different from a standard model is also a useful frame for thinking about why improvements like those in Sonnet 5 translate into real productivity gains rather than just benchmark numbers.
Claude Sonnet 5 vs GLM-5.2: What the Numbers Actually Show
Z.ai released GLM-5.2 around the same time as Claude Sonnet 5, and the benchmark comparison between the two is close enough that it warrants a direct look.
On the two benchmarks where both models have been evaluated:
Benchmark
GLM-5.2
Claude Sonnet 5
Terminal-Bench 2.1
81.0
80.4
SWE-bench Pro
62.1
63.2%
The scores are nearly identical. GLM-5.2 edges Sonnet 5 on Terminal-Bench 2.1 by 0.6 points. Sonnet 5 edges GLM-5.2 on SWE-bench Pro by 1.1 points. Neither model dominates the other on raw benchmark performance.
Where they diverge is on everything else:
Model access: GLM-5.2 is MIT-licensed and ships open weights, you can self-host it. Claude Sonnet 5 is proprietary and API-only.
Pricing: GLM-5.2 costs $1.4 per million input tokens and $4.4 per million output tokens. Claude Sonnet 5 introductory pricing is $2 and $10 respectively and rises to $3/$15 after August 31.
Ecosystem: Claude Sonnet 5 sits inside Anthropic’s full toolchain; Claude Code, Claude Cowork, MCP integrations, and the existing API ecosystem many teams are already building on.
source: shirish/x
The honest read: if benchmark parity is sufficient and your team has the infrastructure to self-host, GLM-5.2 is a compelling cost argument, especially for high-volume output workloads where the per-token gap compounds quickly. If you need API reliability, a managed safety layer, or tight integration with tools like Claude Code, Sonnet 5 is worth the premium.
This is the same decision framework that matters across most proprietary-vs-open-weights comparisons. The benchmarks rarely settle it, deployment requirements and total cost of ownership usually do.
Frequently Asked Questions
Is Claude Sonnet 5 available for free users?
Yes. As of June 30, 2026, Claude Sonnet 5 is the default model on Anthropic’s Free and Pro plans. It is also available to Max, Team, and Enterprise users.
What is the API model string for Claude Sonnet 5?
Developers access it via claude-sonnet-5 through the Claude API.
How does Claude Sonnet 5 pricing compare to Sonnet 4.6?
Sonnet 4.6 was priced at $3 per million input tokens and $15 per million output tokens. Claude Sonnet 5 launches at $2 and $10 respectively through August 31, 2026, making the introductory transition cost-neutral or better for most workloads. Note the updated tokenizer — inputs may expand 1.0 to 1.35 times in token count, so run workload-specific tests before drawing final cost conclusions.
Is Claude Sonnet 5 safer than Sonnet 4.6?
In most respects, yes. Anthropic’s safety evaluations show lower rates of undesirable behavior, reduced hallucination, better prompt injection resistance, and stronger refusal of malicious requests compared to Sonnet 4.6.
When should I use Sonnet 5 versus Opus 4.8?
Sonnet 5 covers most agentic and coding workflows at lower cost. Opus 4.8 is still the better choice for the highest-complexity reasoning tasks and cybersecurity work where reduced guardrails are needed and performance margins matter. If your tasks sit in between, Sonnet 5 at extra-high effort is worth testing before defaulting to Opus.
Does Claude Sonnet 5 support Claude Code?
Yes. Sonnet 5 is available in Claude Code, and rate limits across Claude Code have been increased to support the higher token usage that comes with extended effort levels.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.